Shell Programming
2016年11月07日 Monday, 发表于 纽约
如果你对本文有任何的建议或者疑问, 可以在 这里给我提 Issues, 谢谢! :)
Today, I want to summarize some useful shell programming for ease of reference. These are just some basic commands but I used to forget them and have to Google them over and over and over again.
Overview
- Basic Bash Shell
- Manipulate Output
- Loops and Conditionals
- Workig with Remote Server
- Shell Scripts
- A Simple Practice Task:Sort CitiBike Data
- Reference
1. Basic Bash Shell
First, enter your “Terminal”. The most useful and common commands as follows:
-
jl7333@server:~$ : it shows my username(jl7333), hostname(server),my current working directory(~), showing that I am working as a normal(unprivileged) user($).
-
ls :list the contents of the directory you are in. (ls -l, ls -lt, ls -ltr, you can check using ls –help)
-
pwd :print working directory
-
mkdir directory_name :create a new directory inside our current directory
-
cd directory_name :change directory
-
cd :takes you to your home directory
-
cd .. :takes you to the one level higher directory
-
/home/jl7333 : using “/” can give us a full path
-
nano filename.txt :create a file, open it for editing. (ctrl+o to write, then “enter”,then ctrl+x to exit)
-
cat filename.txt :see the contents of a file, print the contents of the file to the terminal output
-
cp filename1.txt filename2.txt :copy a file from file1 to file2
-
mv filename1.txt mycopy.txt :move(or rename) a file
-
rm mycopy.txt :delete a file (Be very, very careful!)
-
echo :to print a quoted string to the terminal output
-
a=”hello world” :saving string in a variable, echo $a, will print “hello world”
-
history :see your command history all at once.
-
!1 :run a command that appears as number 1 in your history
2. Manipulate Output
First, we need to find some data for practice, for example: run
1 | wget https://www.*****.com/README.txt |
to get data from the Internet. Then use
1 | cat README.txt |
to see the contents of the file. But sometimes the file is too large that you don’t want to print all the contents in the terminal output. To see the beginning of the file, use
1 | head README.txt |
To see the tail of the file, use
1 | tail README.txt |
Also, we can specify the number of lines in the output, use
1 2 | head --lines=3 README.txt tail --lines=3 README.txt |
To show full page at a time, use (enter “Enter” to scroll through the file, enter “q” to quit)
1 | less README.txt |
To count the number of lines of the output file, use
1 | wc -l README.txt |
To see lines that contain word “book”, use
1 | grep "book" README.txt |
To see lines that contain word “book”, the save them to a .txt file ( “>” means to redirect the output)
1 | grep "book" README.txt > book.txt |
| To find the number of lines that contain word “book”, use ( “ | ” means send output of “grep” to “wc” ) |
1 | grep "book" README.txt | wc -l |
Note: “>” means cover the original content in the file. “»” means not cover, new data will append to the file instead.
3. Loops and Conditionals
Like most of the programming languages, Bash supports loops and conditionals.
1 2 3 | for i in 1 2 3; do echo "$i" done |
The blank in the first line of the code is crucial and you cannot omit it.
1 2 3 4 | for i in $( seq 1 10 ) do echo "$i" done |
Here, use $ to access the value of a variable, and we can name our variable whatever we want:
1 2 3 | for animal in "cat" "dog" "monkey" "bird"; do echo "I am a $animal" > "$animal".txt done |
This will automatically create 4 txt files, the name of these files are the animal’s name and the contents of these files are “I am a *****”
We can also loop all the files, for example,
1 2 3 | for file in *.txt; do echo "There is a file called $file" done |
We can also use “if” statements in BASH,
1 2 3 4 5 | i=0 if [ $i -eq 0 ] then echo "The value is zero!" fi |
Then the output of terminal will print “The value is zero!” I give some simple exercises, you can try them.
- Exercies1: Print a message only if a string variable starts with “c” (example)
1 2 3 4 5 6 | for animal in "cat" "dog" "monkey" "bird"; do
if [[ $animal == c* ]]
then
echo "$animal starts with c"
fi
done
|
-
Exercies2: Print a message only if the file named in the loop variable exists
-
Exercies3: Print a message only if a string variable is equal to either “yes” or “no”
-
Exercies4: Print a message only if the strings in two different variables are the same
-
Exercies5: Print a message only if an integer value is greater than 10
4. Workig with Remote Server
In the previous section, we have used “wget” to get data files from the Internet onto our local system. Now we need to copy files from a remote system which we access with “SSH” to our local machine. First, we need to log in the remote server, you need to know the server’s name and password.
1 | ssh jl7333@server_name |
Then use scp to transfer files, the syntax is:
1 | scp source destination |
Attention: you should work in your local laptop system whenever you want to fetch files or send files. Fetchfiles to current directory:
1 | scp jl7333@server.nyu.edu:~/README.txt . |
This README.txt file is under the home directory in the remote server, “.” denotes “here”. If you want to send files to the remote server, use:
1 | scp README.txt jl7333@server.nyu.edu:~/README_2.txt |
Sometimes we want to upload files to the Internet (opposite process of wget), use:
1 | curl --upload-file ./README.txt https://www.*****.com/README.txt |
This will return a URL which you can see and download the file you have just uploaded.
5. Shell Scripts
Now we need to do something more complicated, we need to create a workflow. Save all the steps in one file, and run this file whenever we need. It is called Shell Script. First, we create a file use:
1 | nano hello.sh |
Then write some codes in your .sh file, like this:
1 2 3 | #!/bin/bash echo "Hello World" |
The first line is to tell our operation system to using BASH as interpreter. Notice the .sh file is not executable now, we need to modify the mode.
1 | chmod a+x hello.sh |
Now we could run it using:
1 | ./hello.sh |
or
1 | bash hello.sh |
Sometimes the program is very time-consuming. It is useful to leave it running and come back later when we work on a remote system.
1 2 3 4 5 6 | #!/bin/bash for i in $(seq 100); do echo "on iteration $i" sleep 30 done |
This script need to run for a long time, so we first start a new screen session with
1 | screen -S "jun_new_session" |
Then start this time-consuming program in this new session. Then detach from your current screen new session with “ctrl+A+D” Your script is still running! Don’t worry! Now you can do something else. To resume your session, run
1 | screen -ls |
To lise all the sessions,then run
1 | screen -R jun_new_session |
to re-attach to your running session.
6. A Simple Practice Task:Sort CitiBike Data
In this exercise, our goal is to retrieve and process a set of data files about CitiBike. We get the CitiBike data from 2016-01 to 2016-09. The data structure is .csv file like this:
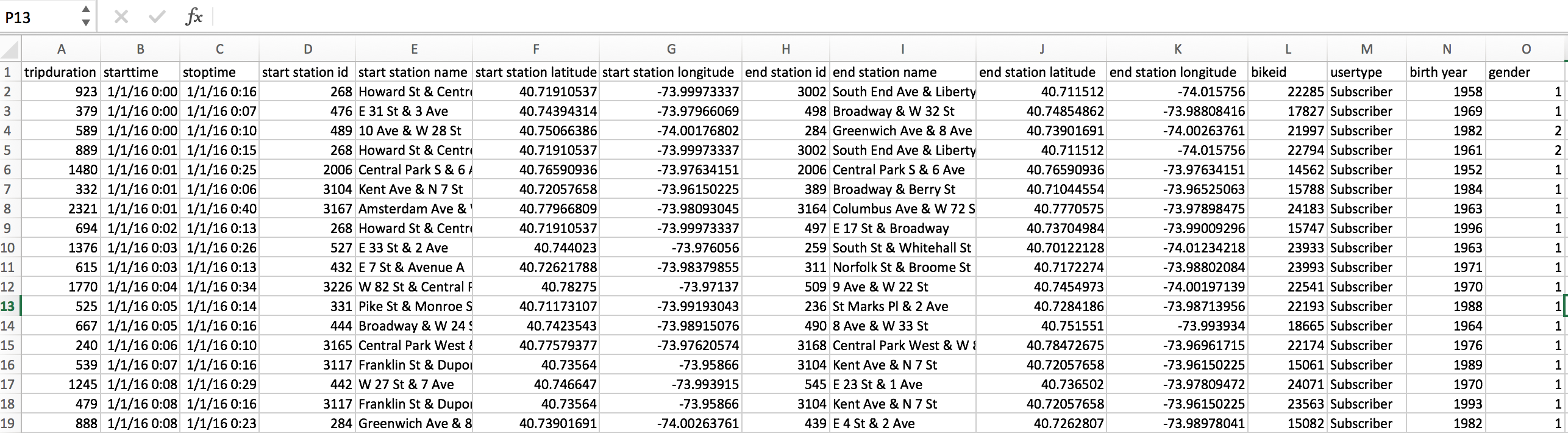
Our output should be a file in which each row is the name of a station and the number of times it appears as either the “start station” or “end station” in the dataset. The file should be sorted so that the most popular stations are at the top. We should write all the code in one shell script so that we can reproduce in the future.
Hints: first use “wget” to get data from the Internet, then use “unzip” to extract files. Using “awk” to print data you want, then “sort” “uniq” “wc”
My code as follows:
1 2 3 4 5 6 7 8 9 10 | #!/bin/bash echo "geting data start!" for i in $( seq 1 9 ); do wget http://witestlab.poly.edu/bikes/20160${i}-citibike-tripdata.zip mv 20160${i}-citibike-tripdata.zip ~/citibike/data/20160${i}-citibike-tripdat$ unzip ~/citibike/data/20160${i}-citibike-tripdata.zip mv 20160${i}-citibike-tripdata.csv ~/citibike/data/20160${i}-data.csv done echo "geting data end!" |
1 2 3 4 5 6 7 8 9 10 11 | #!/bin/bash echo "process star" for i in $( seq 1 9 );do awk -F "\"*,\"*" '{print $5}' ~/citibike/data/20160${i}-data.csv >> ~/citibik$ awk -F "\"*,\"*" '{print $9}' ~/citibike/data/20160${i}-data.csv >> ~/citibik$ done echo "sort data start" sort ~/citibike/data/2016-station.txt | uniq -c > ~/citibike/data/sort.txt sort -r -n -k 1 -t " " ~/citibike/data/sort.txt > ~/citibike/data/result.txt echo "done!" |
The result is:
1 2 3 4 5 6 7 8 9 10 11 12 | jl7333@server:~/citibike/data$ head result.txt 221327 Pershing Square North 158631 West St & Chambers St 153278 W 21 St & 6 Ave 153254 E 17 St & Broadway 150042 Broadway & E 22 St 129900 W 20 St & 11 Ave 129170 12 Ave & W 40 St 127663 Greenwich Ave & 8 Ave 126638 8 Ave & W 33 St 126540 Cleveland Pl & Spring St jl7333@server:~/citibike/data$ |
It shows that Pershing Square North station is the most popular station in which bikes are used for 221327 times in the past nine months. Maybe it should put more bikes there in the future.
6. Reference
1.Scientific Computing Workshop from NYU Tandon Department of ECE
2.Stack Overflow